





Tu jesteś



Niezależnie od tego czy używamy Springa czy też innego rozwiązania do tworzenia systemu, dane w nim przetwarzane muszą być zapisane, by po ponownym uruchomieniu można było pracować na ich zapamiętanej wersji.
Najpowszechniejszym rozwiązaniem, które daje nam taką możliwość są bazy danych. Istnieją bazy relacyjne oparte o język SQL
oraz bazy no SQL, które nie zachowują relacji, a opierają się na odpowiednio przygotowanej strukturze indeksów.
W bieżącym rozdziale przedstawimy krótką zajawkę na temat relacyjnych baz danych, a także wypiszemy kilka ciekawych adresów internetowych, na podstawie których będziecie mogli budować swoją wiedzę o bazach i języku SQL.
W celu zapisania takich danych musimy je jakoś logicznie podzielić. Stosując nazewnictwo anglojęzyczne jesteśmy w stanie wyznaczyć takie podmioty (byty) jak event, event category, ticket, participant (uczestnik) itp. W ten sposób kształtuje się nam automatycznie podział na tabele w bazie. Tworzymy zatem tabele:
 I teraz najważniejsze. Jeśli chcemy powiązać relacją dane z tabeli events z danymi z tabeli events_categories musimy wpisać do tabeli events identyfikatory
kategorii, do których należą kolejne wydarzenia. Tak więc oprócz wcześniej wspomnianych kolumn dodajemy do tabeli events kolumnę z tak zwanym kluczem obcym, czyli identyfikatorem pochodzącym
z innej tabeli i wskazującym na zaistnienie relacji między tymi tabelami. Innymi słowy, teraz lista kolumn w tabeli events będzie wyglądała tak:
I teraz najważniejsze. Jeśli chcemy powiązać relacją dane z tabeli events z danymi z tabeli events_categories musimy wpisać do tabeli events identyfikatory
kategorii, do których należą kolejne wydarzenia. Tak więc oprócz wcześniej wspomnianych kolumn dodajemy do tabeli events kolumnę z tak zwanym kluczem obcym, czyli identyfikatorem pochodzącym
z innej tabeli i wskazującym na zaistnienie relacji między tymi tabelami. Innymi słowy, teraz lista kolumn w tabeli events będzie wyglądała tak:
 W ten sposób nawiązaliśmy naszą pierwszą relację! Co więcej, możemy nawet określić, że relacja ta jest typu jeden do wiele, gdyż docelowo
możemy mieć wiele wydarzeń w tabeli events wskazujących na jeden i ten sam identyfikator kategorii. Wszystkie mecze siatkarskie będą miały ustawione id kategorii równe 3.
W ten sposób nawiązaliśmy naszą pierwszą relację! Co więcej, możemy nawet określić, że relacja ta jest typu jeden do wiele, gdyż docelowo
możemy mieć wiele wydarzeń w tabeli events wskazujących na jeden i ten sam identyfikator kategorii. Wszystkie mecze siatkarskie będą miały ustawione id kategorii równe 3.
Jakie zatem typy relacji wyróżniamy w relacyjnej bazie danych? Dokładnie trzy:
Trzy rodzaje relacji
Klucze w bazach danych
Po stworzeniu tabel wykonujemy zapytania typu DML (Data Manipulation Language). Zapytaniami pochodzącymi z tej grupy są: SELECT, INSERT, UPDATE i DELETE. Dzięki nim możemy wprowadzać dane do bazy, modyfikować je oraz pobierać i usuwać. Zerknijmy teraz na kilka przykładów.
W bieżącym rozdziale przedstawimy krótką zajawkę na temat relacyjnych baz danych, a także wypiszemy kilka ciekawych adresów internetowych, na podstawie których będziecie mogli budować swoją wiedzę o bazach i języku SQL.
Baza danych - Co to jest?
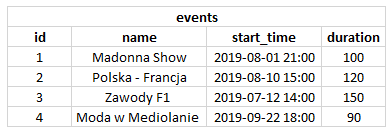
Baza danych to w najprostszym ujęciu zbiór odpowiednio uporządkowanych i powiązanych ze sobą danych. Dane są przechowywane w tabelach, czyli tematycznie wydzielonych "kontenerach". Tworząc prosty program lub bardziej rozbudowany system, zwykle poruszamy się w konkretnym obszarze tematycznym występującym w rzeczywistości. I tak na przykład jeśli budujemy system do zakupu biletów na wydarzenia kulturalne, mamy do zapamiętania dane opisujące zarówno samo wydarzenie (nazwa, godzina rozpoczęcia, czas trwania itp.), jak również wiele innych elementów powiązanych (kategoria wydarzenia, wykonawcy, bilety).W celu zapisania takich danych musimy je jakoś logicznie podzielić. Stosując nazewnictwo anglojęzyczne jesteśmy w stanie wyznaczyć takie podmioty (byty) jak event, event category, ticket, participant (uczestnik) itp. W ten sposób kształtuje się nam automatycznie podział na tabele w bazie. Tworzymy zatem tabele:
- events - tutaj będziemy przechowywać wszystkie podstawowe dane o wydarzeniach
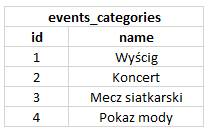
- events_categories - w tym miejscu zapiszemy listę możliwych kategorii, na przykład: koncert, mecz, wyścigi rajdowe, pokaz mody itp.
- tickets - tu przechowamy podstawowe dane dotyczące biletów, np. cena, wariant itp.
- participants - w tym miejscu zachowamy listę uczestników wydarzenia (np. wykonawców w trakcie koncertu)
Rekordy w tabelach
Tabele zawierają kolumny. Wygląda to trochę tak jak w arkuszu kalkulacyjnym. Kolumny mają swoje nagłówki, a wiersze przechowują dane w kolejnych kolumnach. Każdy taki wiersz w bazie danych nazywany jest rekordem albo krotką (z ang. tuple). Jakiego typu dane mogą znaleźć się w rekordach? Wszystko zależy od typu danych dla każdej z kolumn. Kolumny najczęściej mogą być typu numerycznego (liczby), tekstowego lub przechowującego datę czy dane binarne, na przykład obrazki czy dokumenty. Dla przykładu tabela events mogłaby zawierać kolumny:- id - wygenerowany identyfikator eventu
- name - nazwa eventu
- start_time - data i czas rozpoczęcia eventu
- duration - czas trwania eventu (na przykład w minutach)
Relacje między tabelami
Pojedyncze tabele nie odwierciedlają w pełni mocy jaką są obdarzone relacyjne bazy danych. O ich prawdziwej sile stanowią właśnie wspomniane relacje. Zobaczmy teraz jak wygląda przykładowa relacja. Mamy tabelę events_category, która zawiera dwie kolumny:- id - wygenerowany identyfikator kategorii
- name - nazwa kategorii
- id - wygenerowany identyfikator eventu
- name - nazwa eventu
- start_time - czas rozpoczęcia eventu
- duration - czas trwania eventu
- events_categories_id - identyfikator kategorii pochodzący z tabeli categories_events
Jakie zatem typy relacji wyróżniamy w relacyjnej bazie danych? Dokładnie trzy:
- jeden do jeden - rekord tabeli wiąże się bezpośrednio tylko i wyłącznie z jednym rekordem innej tabeli i na odwrót
- jeden do wiele - rekord jednej tabeli wiąże się bezpośrednio z wieloma rekordami drugiej tabeli, przy czym rekord drugiej tabeli wiąże się z tylko jednym rekordem tej pierwszej; jeśli spojrzymy na tę relację z drugiej strony możemy mówić o występowaniu relacji wiele do jednego
- wiele do wiele - rekord jednej tabeli wiąże się bezpośrednio z wieloma rekordami drugiej tabeli oraz rekord drugiej tabeli wiąże się z wieloma rekordami tej pierwszej (wtedy łączenie następuje przez tabele łączącą)
Trzy rodzaje relacji
Klucze w bazach danych
SQL - Structured Query Language
SQL to język zapytań umożliwiający komunikację się z bazą danych. W ten sposób możemy wykonywać zapytania typu DDL (Data Definition Language), które odpowiadają za tworzenie i modyfikowanie struktur takich jak tabele, indeksy, widoki. Najważniejszymi zapytaniami z tej grupy są CREATE, DROP, ALTER.Po stworzeniu tabel wykonujemy zapytania typu DML (Data Manipulation Language). Zapytaniami pochodzącymi z tej grupy są: SELECT, INSERT, UPDATE i DELETE. Dzięki nim możemy wprowadzać dane do bazy, modyfikować je oraz pobierać i usuwać. Zerknijmy teraz na kilka przykładów.
- CREATE - Tworzenie tabeli
CREATE TABLE events (id int, name varchar(10), start_time date, duration int);
- INSERT - Wpisanie wiersza do tabeli
INSERT INTO events (1,'Madonna Show', '2019-08-01 21:00', 100);
- SELECT - Pobranie wierszy z tabeli
SELECT * FROM events;



Mapa umiejętności programisty Java
Nie jesteś biegły w Javie?
Zobacz nasz kurs programowania Java
Interesuje Cię szerszy zakres wiedzy?
Zerknij na Java board
Polub nas na
Facebooku:





Kliknij O nas .
Pozycjonowanie stron: Grupa TENSE